-
Last night I taught functional programming and {purrr}, which was one of the hardest lectures/labs to put together for the #rstats course. So far, the students seem to be getting it, which I'm grateful for! youtu.be/HiLrucrzYJM?t=1947Permalink On twitter.com
♻️ 16 Retweets ❤️ 109 Favorites Mood +3 🙂
-
We did go over functions and lists before this, so they were fresh in their minds. One thing I fell down on - anonymous functions. I'm not a fan of the (.x) notation, so we'll talk more about that next time.Permalink On twitter.com
-
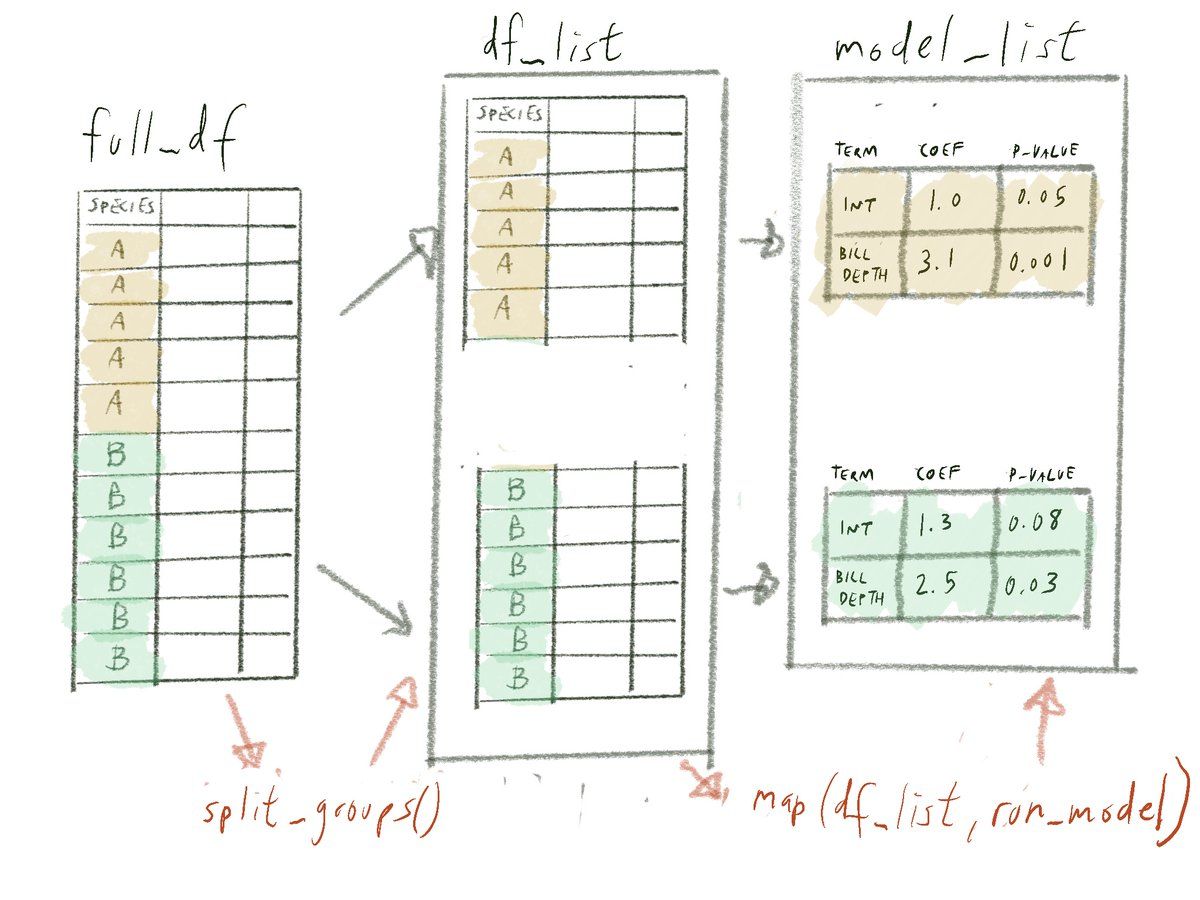
I found it a hard lesson to manage cognitive load in. There are so many little parts to {purrr}, and you have to introduce them slowly. For example: map always works on a list, and returns a new list with the same length.Permalink On twitter.com
-
WhereasPermalink On twitter.com
reduce()applies an operation by pairs, until you have a single entity.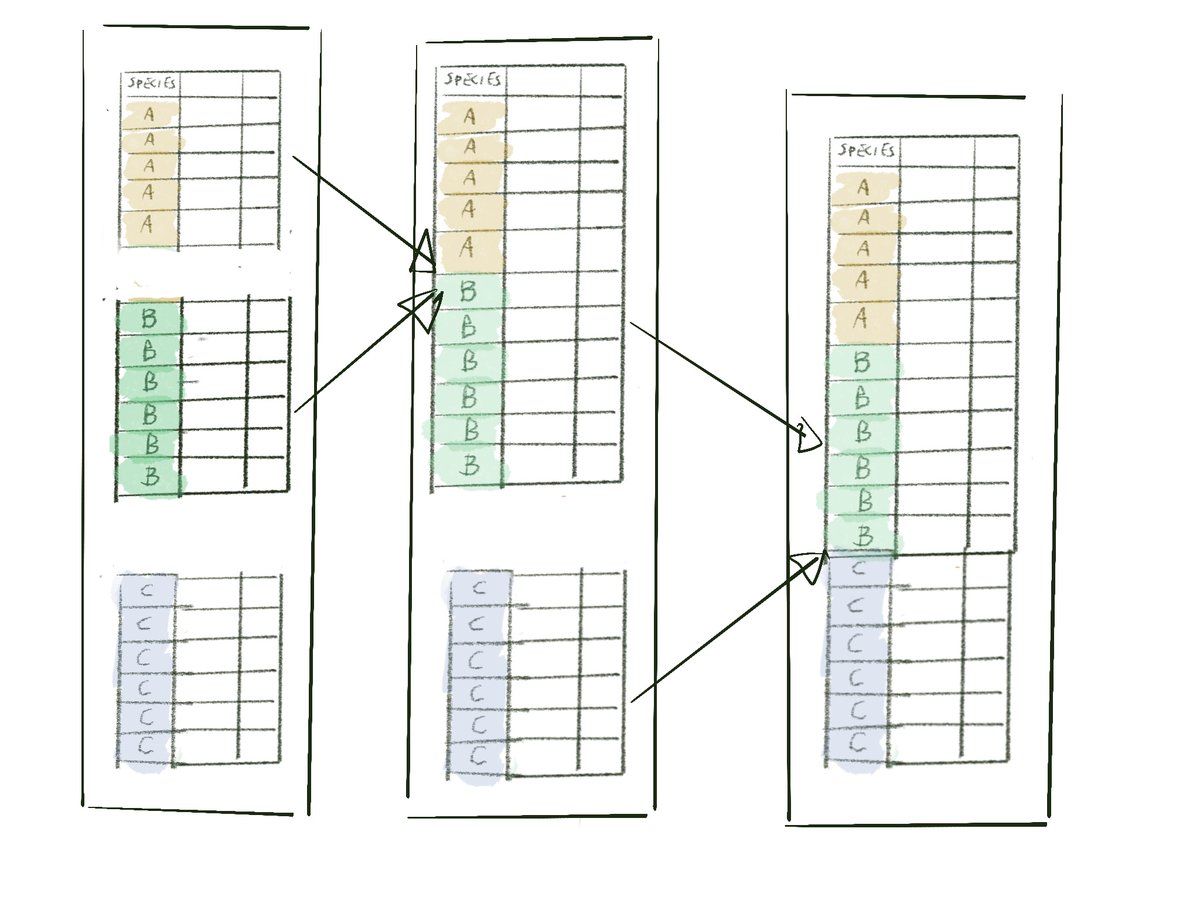
-
Permalink On twitter.com
map_df()is one of the most useful functions, but I think it's better to introducemap()andreduce()as separate steps, because otherwisemap_df()seems like magic, which I try not to do. It's better to understand what's under the hood. -
The main use case we talked about was loading a folder of files that has the same format, which is a pretty common use case. My point: once you get a bunch of data.frames in a list, the world is your oyster. I will probably savePermalink On twitter.com
nest_by()and list-columns for the future. -
I guess that's one thing that I have struggled with: list-columns are super useful, but how to transition from a list of data.frames to a list-column data.frame and using them in {purrr}. It felt like one inception too many for the lesson, so we skipped it.Permalink On twitter.com
-
I ended with talking about the map_* variants, mostlyPermalink On twitter.com
map_df(), and failing gracefully usingpossibly(). It was a lot of lecture/lab, so I'm proud of the students for getting through it. -
One thought: It's super useful to have named lists of data.frames, especially when usingOn twitter.com
split_groups(). But you have to go through some hoops to name them. Basesplit()gives you a named list, but you have to use the (.) annotation to refer to the column you split on.