
Why burro(w) into your data?
Exploratory Data Analysis (EDA) is highly visual and can be a motivating entry point into data science and analysis. burro attempts to make EDA accessible to a larger audience by exposing datasets as a simple Shiny App that can be shared via shinyapps.io or other Shiny hosts. You can see an example here: https://tladeras.shinyapps.io/nhanes_explore/
We use burro as an introductory tool for EDA by using it in “data scavenger hunts”, where groups of students are given specific questions to answer about the data, and then have to show their fellow students the answer and how the discovered it. Looking at the data together is vital to building understanding of the data together.
By concentrating on the data visualization first, burro apps let us have conversations about the data, and hopefully motivate students to learn more tools of EDA such as ggplot, visdat, and skimr.
Installing burro
burro is currently only on github and not on CRAN yet. To install it, run the following.
install.packages("remotes")
remotes::install_github("laderast/burro")Dataset requirements
burro expects a dataset as a data.frame or data.table. It attempts to automatically figure out which variables to use in specific visualizations.
If the variable is categorical, then the variable should be cast as factor() or ordered(). For example:
data(mtcars)
mtcars$cyl <- factor(mtcars$cyl)
mtcars$gear <- factor(mtcars$gear)
explore_data(mtcars)burro can utilize an outcome variable, which should be categorical/factor.
It’s on my list of things to do to make burro adaptive to the data passed into it, but it currently is pretty inflexible about these two things.
An optional (though helpful) requirement is to have a data dictionary which has a column called variableNames that defines each variable in the dataset.
Running burro on NHANES Data
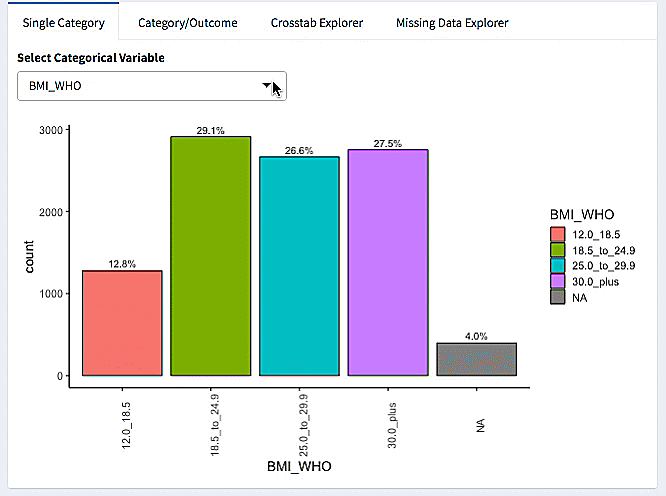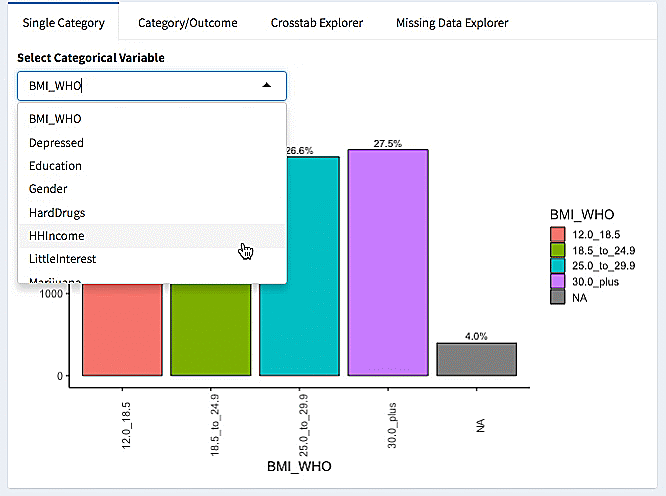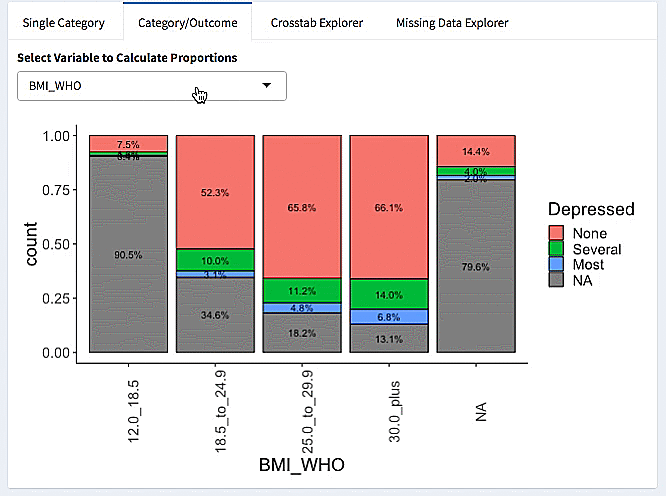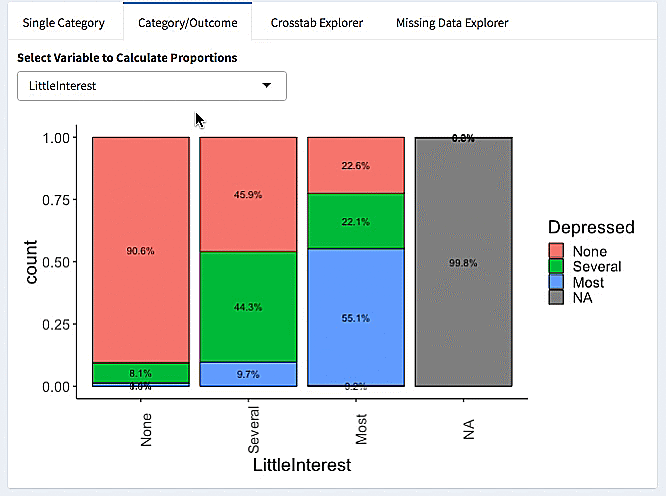
Here we make a burro app using the explore_data option for the NHANES (National Health and Nutrition Examination Survey) data. We specify our covariates, and our outcome of interest (Depressed, the number of depressive episodes).
You can see the burro app for the NHANES data here: https://tladeras.shinyapps.io/nhanes_explore/
library(burro)
#make sure that NHANES package is installed
library(NHANES)
data(NHANES)
data_dict <- readr::read_csv(system.file("nhanes/data_dictionary.csv", package="burro"))
##specify outcome variable here
outcome <- c("Depressed")
explore_data(dataset=NHANES, data_dictionary=data_dict, outcome_var=outcome)
Running burro on biopics data from fivethirtyeight
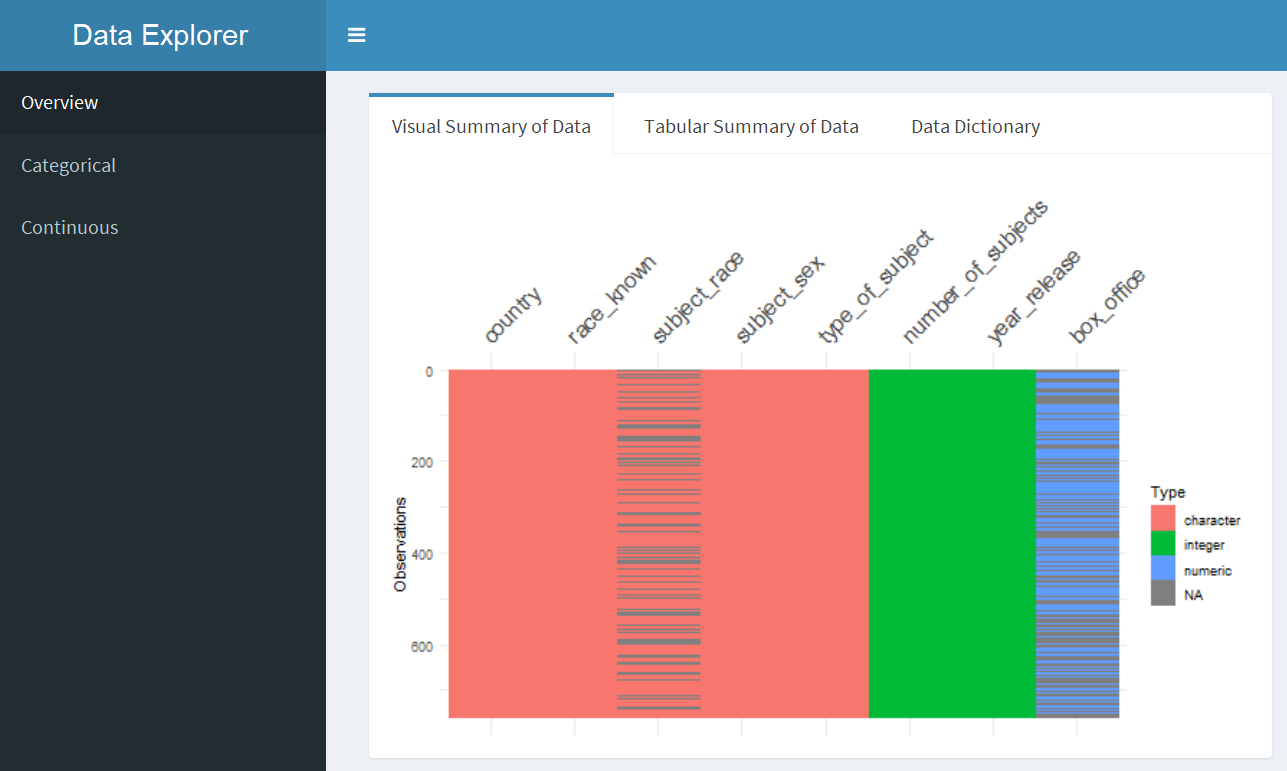
We can examine the biopics dataset using burro. We specify our outcome_var to be subject_sex, so we can examine everything through the facet of gender.
library(burro)
library(fivethirtyeight)
data(biopics)
explore_data(biopics, outcome_var = "subject_sex")
Run burro on diamonds
library(ggplot2)
data(diamonds)
burro::explore_data(diamonds, outcome_var="cut")Acknowledgements
burro uses many wonderful packages developed by Nicholas Tierney and rOpenSci: visdat, naniar, and skimr.
burro was partially developed with funding from Big Data to Knowledge (BD2K) and a National Library of Medicine T15 Training Grant supplement for the development of data science curricula.
The burro hex sticker uses clipart designed by Freepik.
License
burro is released under a MIT license. Please let us know if you are using burro in your work!
Contributing
We want you to contribute! See the contributing link above for more info.